- 进入阿里云的 函数计算 FC (aliyun.com)
- 按照以下图示进行函数创建和部署
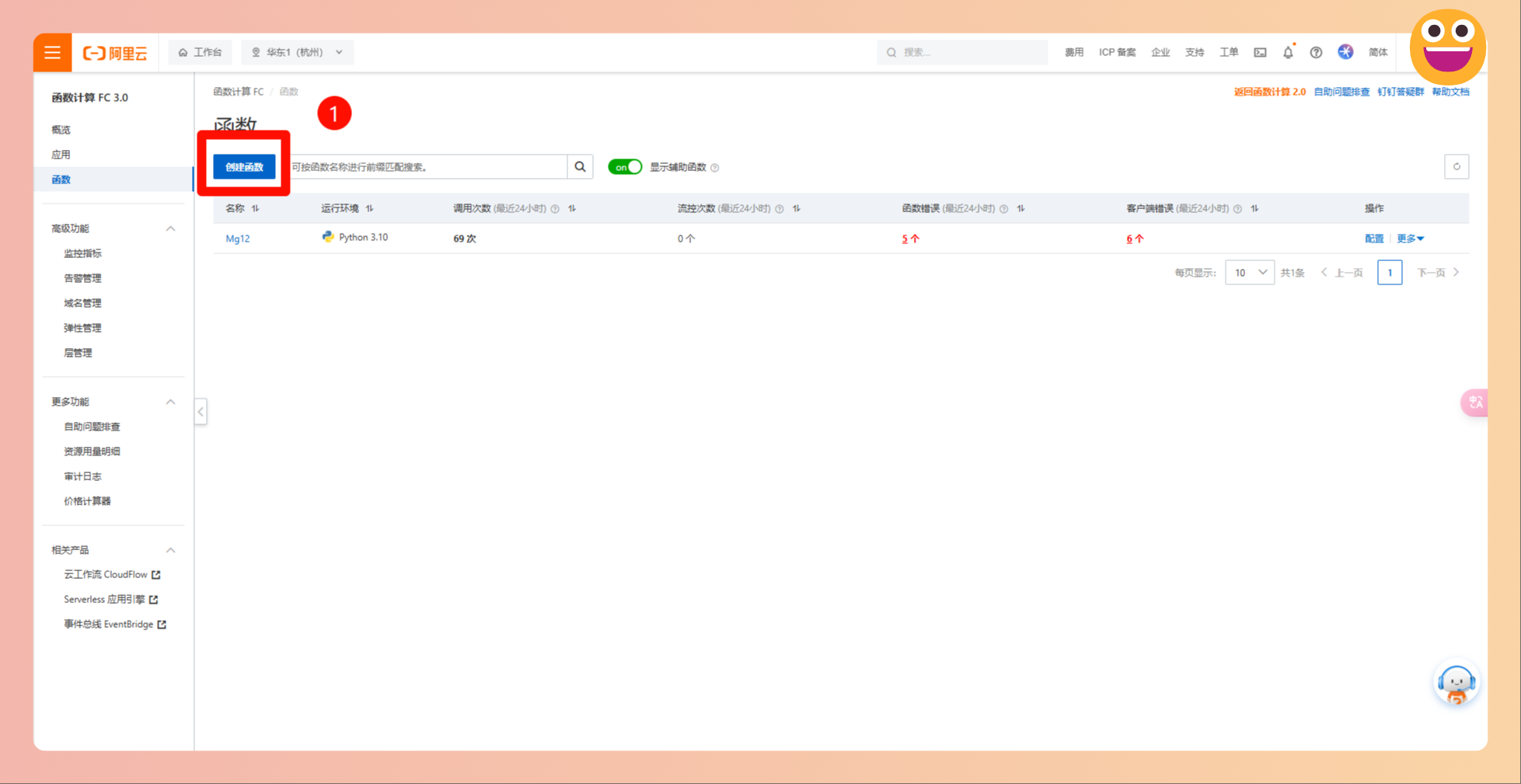
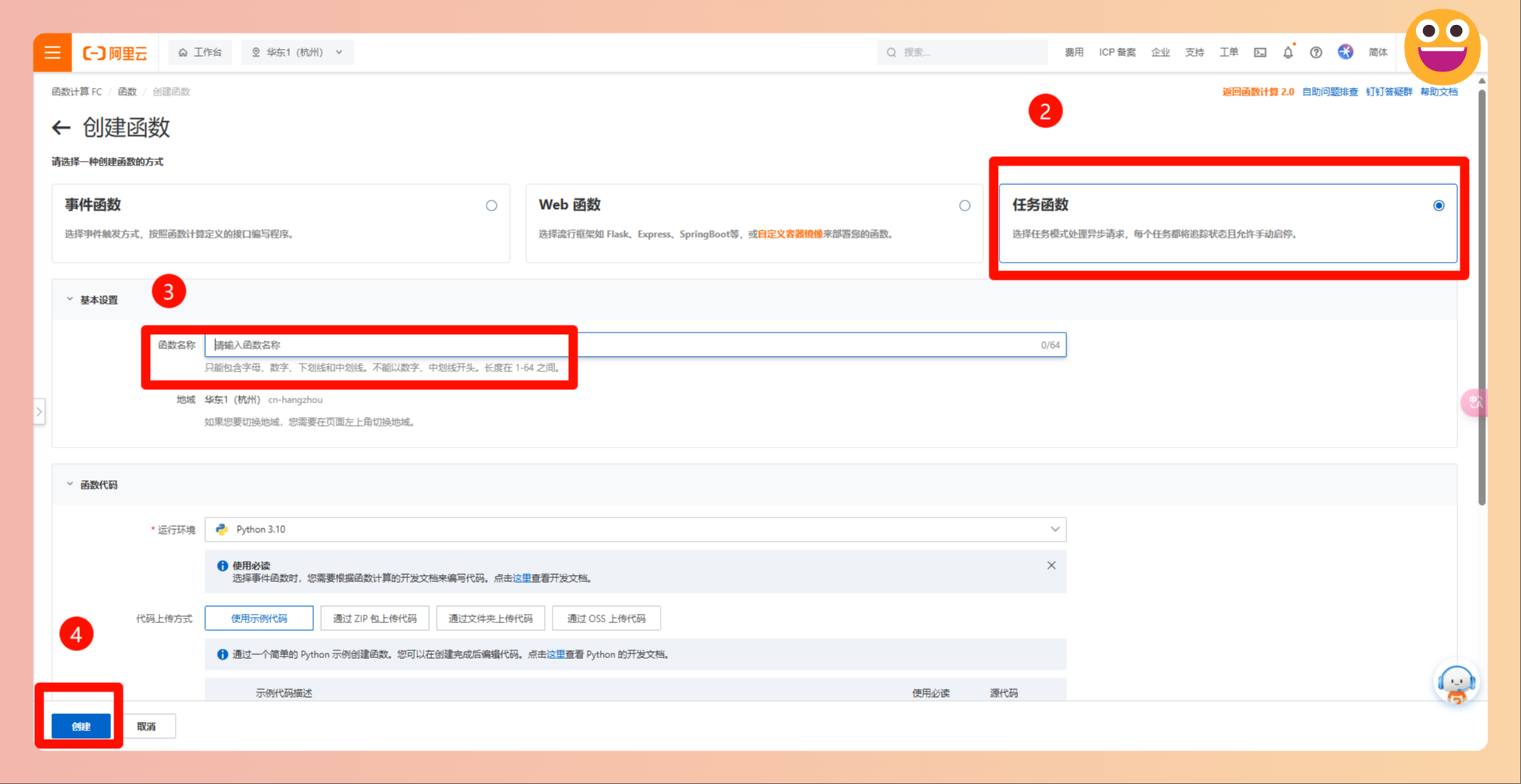
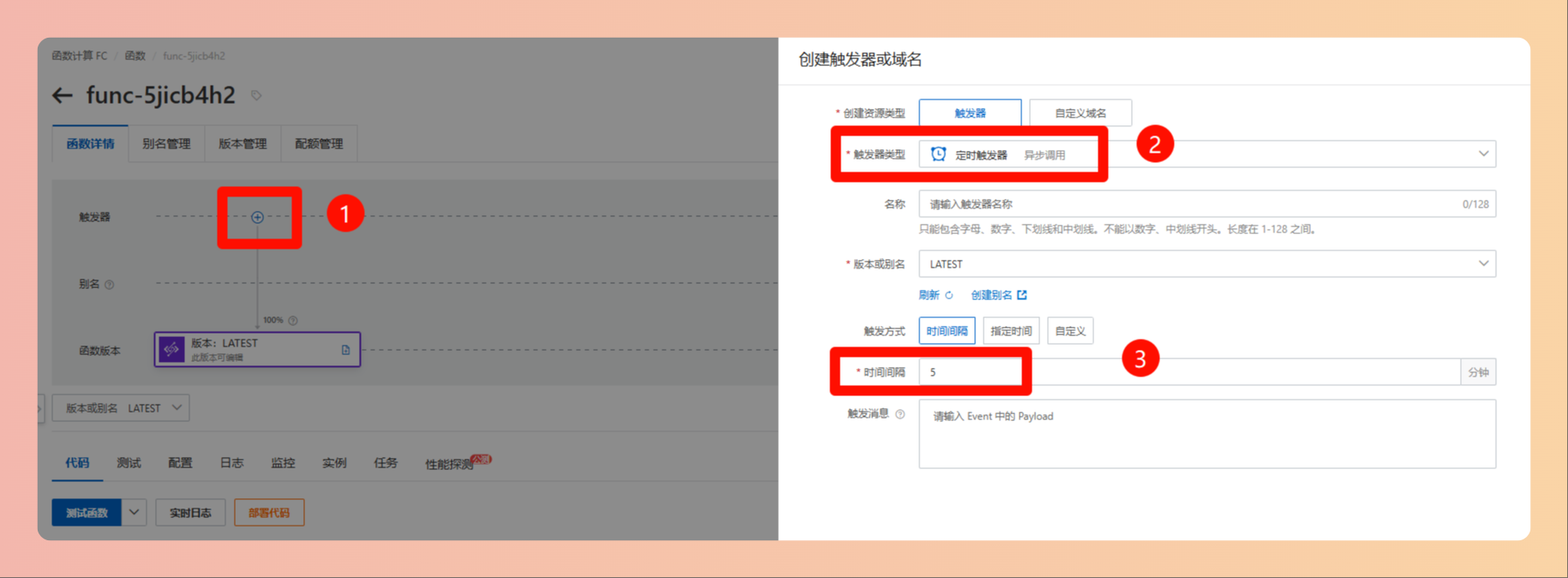
- 开通阿里云 表格存储 (aliyun.com),新建实例,获取公网地址
OTS_ENDPOINT = '公网地址'
OTS_INSTANCE = '实例名称'
创建子用户,在新建策略 RAM 访问控制 (aliyun.com) 中自定义策略选择表格存储的所有权限,然后到子用户添加权限,获取 AccessKey ID 和 AccessKey SECRET,更改以下内容。
OTS_ID = ''
OTS_SECRET = ''
获取企业微信机器人的 API_KEY,更改:
API_KEY = ''
修改 RSS 的相关内容和链接
TABLE_NAME = '' # Table name
XMOL_URL = ''
PUBMED_URL = ''
汇总以下:
# -*- coding: utf-8 -*-
import logging
import time
import requests
import re
from tablestore import *
import tablestore.protobuf.table_store_pb2 as pb2
# Constants
OTS_ENDPOINT = ''
OTS_ID = ''
OTS_SECRET = ''
OTS_INSTANCE = ''
API_KEY = ''
# 如果想更换RSS内容,需要更改以下3个常量
TABLE_NAME = '' # Table name
XMOL_URL = ''
PUBMED_URL = ''
# Global variable to store processed links
processed_links = []
def put_row(client, gid, article):
"""
Insert a row into the table.
"""
primary_key = [('gid', gid)]
attribute_columns = [
('doi', article["doi"]),
('title', article["title"]),
('pub_date', article["pub_date"]),
('journal', article["journal"]),
('impact_factor', article["impact_factor"]),
('authors', article["authors"]),
('abstract', article["abstract"])
]
row = Row(primary_key, attribute_columns)
consumed, return_row = client.put_row(TABLE_NAME, row, return_type=ReturnType.RT_PK)
print(f'Write succeed, consume {consumed.write} write cu.')
print(f'Primary key: {return_row.primary_key}')
def get_range(client):
"""
Get the range of rows from the table.
"""
global processed_links
inclusive_start_primary_key = [('gid', INF_MIN)]
exclusive_end_primary_key = [('gid', INF_MAX)]
columns_to_get = ["doi"]
limit = 90
all_rows = []
consumed, next_start_primary_key, row_list, next_token = client.get_range(
TABLE_NAME, Direction.FORWARD,
inclusive_start_primary_key, exclusive_end_primary_key,
columns_to_get, limit
)
all_rows.extend(row_list)
while next_start_primary_key is not None:
inclusive_start_primary_key = next_start_primary_key
consumed, next_start_primary_key, row_list, next_token = client.get_range(
TABLE_NAME, Direction.FORWARD,
inclusive_start_primary_key, exclusive_end_primary_key,
columns_to_get, limit
)
all_rows.extend(row_list)
for row in all_rows:
processed_links.append(row.attribute_columns[0][1])
return processed_links
def get_latest_items(url, source):
"""
Get the latest items from the given URL based on the source.
"""
if source == 'xmol':
pattern = r"""<div class="it-bold space-bottom-m10">.*?</span>(.*?)</div>.*?<a target="_blank" onclick=.*? href=(.*?)>.*?<div class="div-text-line-one it-new-gary">.*?<em class="it-blue">(.*?)</em>.*?<span style="color: #FF7010;">(.*?)</span>.*?Pub Date : (.*?), DOI:(.*?)</div>.*?<div class="div-text-line-one it-new-gary">(.*?)</div>.*?<div class="div-text-line-three itsmlink">(.*?)</div>.*?"""
elif source == 'pubmed':
pattern = r"""<item>.*?<title>(.*?)</title>.*?<content:encoded>.*?<p xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:mml="http://www.w3.org/1998/Math/MathML" xmlns:p1="http://pubmed.gov/pub-one">(.*?)</p>.*?DOI:<a href=(.*?)>.*?<dc:creator>(.*?)</dc:creator>.*?<dc:date>(.*?)</dc:date>.*?<dc:source>(.*?)</dc:source>"""
matches = re.findall(pattern, requests.get(url).text, re.DOTALL)
return matches
def create_table(client):
"""
Create a table in the database.
"""
schema_of_primary_key = [('gid', 'INTEGER')]
table_meta = TableMeta(TABLE_NAME, schema_of_primary_key)
table_options = TableOptions()
reserved_throughput = ReservedThroughput(CapacityUnit(0, 0))
client.create_table(table_meta, table_options, reserved_throughput)
print('Table has been created.')
def delete_table(client):
"""
Delete the table from the database.
"""
client.delete_table(TABLE_NAME)
print(f'Table \'{TABLE_NAME}\' has been deleted.')
def setup_table(client):
"""
Delete and create the table for initial setup.
"""
try:
delete_table(client)
except Exception as e:
print(f"Error deleting table: {e}")
create_table(client)
def save_new_articles(client, items, source):
"""
Save new articles to the table if they are not already processed.
"""
global processed_links
for item in items:
message, article = get_message_content(item, source)
if article["doi"] not in processed_links:
print(f'{article["doi"]} 未保存,正在保存')
put_row(client, len(processed_links), article) # gid从0开始
# time.sleep(5)
processed_links.append(article["doi"])
def get_message_content(match, source):
"""
Format the message content based on the source.
"""
if source == 'xmol':
title = match[0].strip()
url = f'https://www.x-mol.com{match[1].strip()[1:-1]}'
journal = match[2].strip()
impact_factor = match[3].strip()
pub_date = match[4].strip()
doi = match[5].strip()
authors = match[6].strip()
abstract = re.sub(r'\s*\.\.\.', '', match[7].strip())
elif source == 'pubmed':
title = match[0].strip()
journal = match[5].strip()
impact_factor = ""
pub_date = match[4].strip()
doi = match[2].strip()[16:]
authors = match[3].strip()
abstract = match[1].strip()
article = {
"doi": doi,
"title": title,
"pub_date": pub_date,
"journal": journal,
"impact_factor": impact_factor,
"authors": authors,
"abstract": abstract
}
formatted_content = f"""✅《{title}》
ℹ️Journal: {journal} IF: {impact_factor}
ℹ️Date: {pub_date}
ℹ️Authors: {authors}
ℹ️DOI: https://doi.org/{doi}
ℹ️Abstract: {abstract}"""
return formatted_content, article
def send_to_wechat(content, key):
"""
Send the formatted content to WeChat.
"""
webhook_url = f"https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key={key}"
headers = {
"Content-Type": "application/json"
}
data = {
"msgtype": "text",
"text": {
"content": content
}
}
response = requests.post(webhook_url, json=data, headers=headers)
if response.status_code == 200:
print("Message sent successfully to WeChat!")
else:
print(f"Failed to send message to WeChat. Status Code: {response.status_code}")
def process_items(client, gid, items, source, api_key):
"""
Process the items and send them to WeChat if not already processed.
"""
global processed_links
for item in items:
message, article = get_message_content(item, source)
if article["doi"] not in processed_links:
gid += 1
put_row(client, gid, article)
send_to_wechat(message, api_key)
time.sleep(5)
def main():
"""
Main function to execute the script.
"""
global processed_links
items_xmol = get_latest_items(XMOL_URL, 'xmol')
print(f'当前抓取的RSS数目为:{len(items_xmol)}')
items_pubmed = get_latest_items(PUBMED_URL, 'pubmed')
print(f'当前抓取的Pubmed数目为:{len(items_pubmed)}')
client = OTSClient(OTS_ENDPOINT, OTS_ID, OTS_SECRET, OTS_INSTANCE)
time.sleep(2) # wait for table ready
# # 首次运行时需要创建表
# setup_table(client)
# save_new_articles(client, items_xmol, 'xmol')
# save_new_articles(client, items_pubmed, 'pubmed')
processed_links = get_range(client)
process_items(client, len(processed_links), items_xmol, 'xmol', API_KEY)
process_items(client, len(processed_links), items_pubmed, 'pubmed', API_KEY)
def handler(event, context):
"""
Handler function for the cloud function.
"""
logger = logging.getLogger()
main()
logger.info('hello world')
return 'hello world'
# if __name__ == "__main__":
# main()
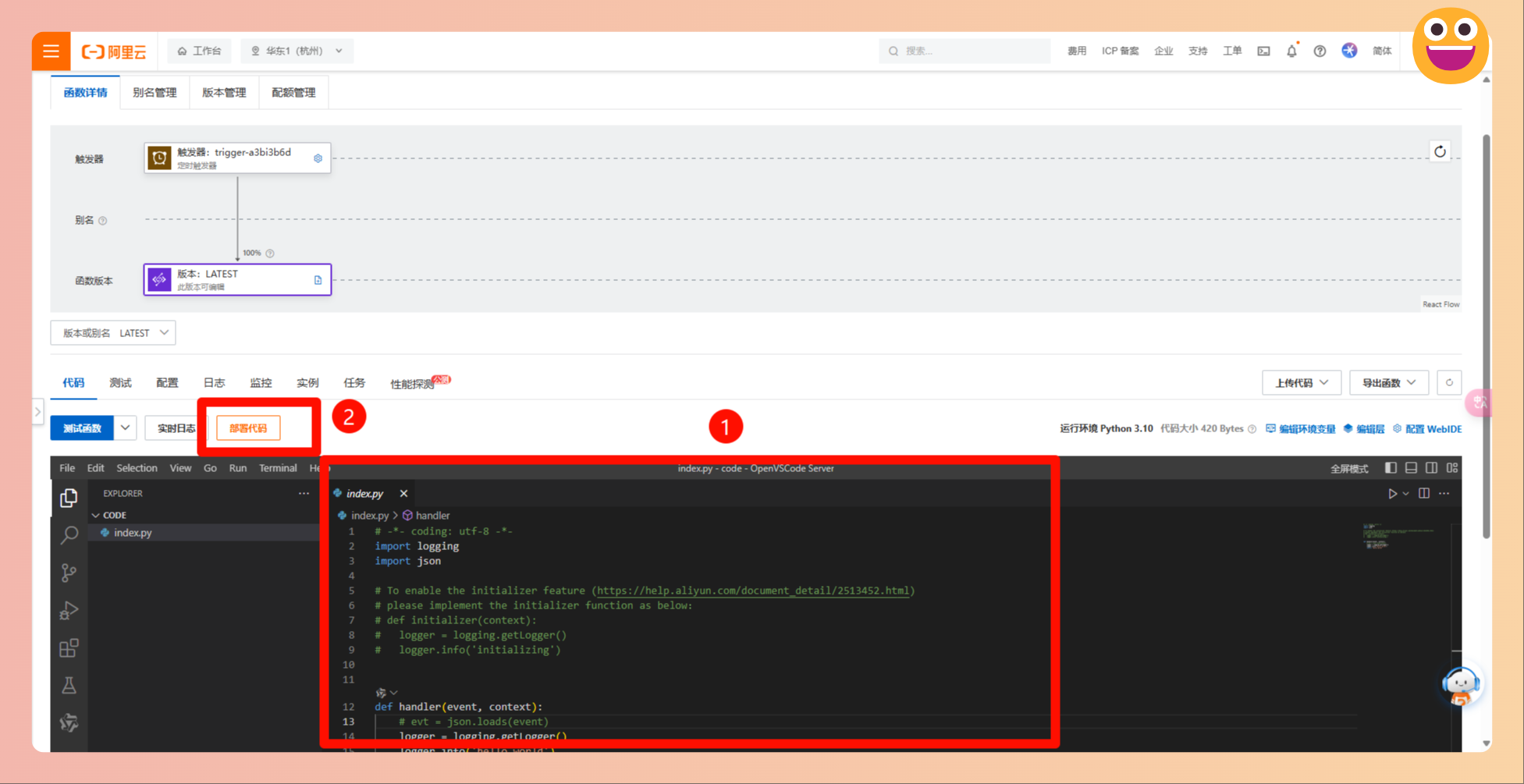
最后
部署和测试就行了!